ANSOLに続いて、24コア XON 2687EW V4マシンでのANSYS17.0並列計算性能を紹介します。
ANSYSライセンス:ANSYSメカニカル、MAX JOB数=1、デフォルトCPU数=2
これにHPCオプションを追加して最大CPU数=6
問題:400万自由度、線形解析
最大ジョブ数が1なので、常に6CPUで使用するしかないのだが、並列化の効果を調べてみた。
先ずは、SMP版 SPARSE法とPCG法での比較を示す。
CPU数の指定は、 DOS> ansys170.exe -np 6 [他オプション]
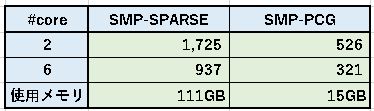
メモリサイズが、128GBだと、この大きさが限界で、これ以上のサイズになるとディスクIOが増えて
極端に遅くなる。また、マッシブな問題なので、当然PCG法が速く、メモリも少ない。
次に Distributed ANSYS (MPP版)を試してみた。
テストマシンには、既にIBM MPI(旧Platfrm MPI)が既にインストールされているので、
Platform-MPI Command Promptを起動して、以下を実行すれば良い。
DOS> ansys170.exe -dis -mpi pcmpi -np 6 [他オプション]
動き出すとCPU毎にモデルが分割され、指定CPU数に対応したANSYS.exeが動き出す。
通常はこれだけでいいのだが、各プロセスのメモリ使用状況を調べていて、バランスが芳しくなかったら
以下のコマンドを入力データに追加してみる。
DDOPTION,AUTO/GREEDY/METIS (指定なき場合は、AUTO)
6CPU、SPRASE&PCG法で、AUTO, GREEDY, METIS の測定結果を示す。
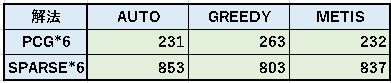
パラメータを変えて何回も実行するのでなければ、AUTO(データ追加なし)で構わないようだ。